Forth (programming language)
| Paradigm | Procedural, stack-oriented, reflective |
|---|---|
| Appeared in | 1970s |
| Designed by | Charles H. Moore |
| Typing discipline | typeless |
| Major implementations | Forth, Inc., Gforth, MPE |
| Dialects | colorForth, MUF, Open Firmware |
| Influenced by | Burroughs large systems, Lisp, APL |
| Influenced | Factor, Cat, PostScript, RPL, REBOL |
Forth is a structured, imperative, reflective, extensible, stack-based computer programming language and programming environment. Forth is sometimes spelled in all capital letters following the customary usage during its earlier years, although the name is not an acronym.
A procedural programming language without type checking, Forth features both interactive execution of commands (making it suitable as a shell for systems that lack a more formal operating system) and the ability to compile sequences of commands for later execution. Some Forth implementations (usually early versions or those written to be extremely portable) compile threaded code, but many implementations today generate optimized machine code like other language compilers.
Although not as popular as other programming systems, Forth has enough support to keep several language vendors and contractors in business. Forth is currently used in boot loaders such as Open Firmware, space applications,[1] and other embedded systems. Gforth, an implementation of Forth by the GNU Project is actively maintained, the last release in December 2008. The 1994 standard is currently undergoing revision, provisionally titled Forth 200x.[2]
Contents |
Overview
A Forth environment combines the compiler with an interactive shell. The user interactively defines and runs subroutines, or "words," in a virtual machine similar to the runtime environment. Words can be tested, redefined, and debugged as the source is entered without recompiling or restarting the whole program. All syntactic elements, including variables and basic operators, appear as such procedures. Even if a particular word is optimized so as not to require a subroutine call, it is also still available as a subroutine. On the other hand, the shell may compile interactively typed commands into machine code before running them. (This behavior is common, but not required.) Forth environments vary in how the resulting program is stored, but ideally running the program has the same effect as manually re-entering the source. This contrasts with the combination of C with Unix shells, wherein compiled functions are a special class of program objects and interactive commands are strictly interpreted. Most of Forth's unique properties result from this principle. By including interaction, scripting, and compilation, Forth was popular on computers with limited resources, such as the BBC Micro and Apple II series, and remains so in applications such as firmware and small microcontrollers. Where C compilers may now generate code with more compactness and performance, Forth retains the advantage of interactivity.
The stacks
Most programming environments with recursive subroutines use a stack for control flow. This structure typically also stores local variables, including subroutine parameters (in a call by value system such as C). Forth often does not have local variables, however, nor is it call-by-value. Instead, intermediate values are kept in a second stack. Words operate directly on the topmost values in the first stack. It may therefore be called the "parameter" or "data" stack, but most often simply "the" stack. The second, function-call stack is then called the "linkage" or "return" stack, abbreviated rstack. Special rstack manipulation functions provided by the kernel allow it to be used for temporary storage within a word, but otherwise it cannot be used to pass parameters or manipulate data.
Most words are specified in terms of their effect on the stack. Typically, parameters are placed on the top of the stack before the word executes. After execution, the parameters have been erased and replaced with any return values. For arithmetic operators, this follows the rule of reverse Polish notation. See below for examples illustrating stack usage.
Maintenance
Forth is a simple yet extensible language; its modularity and extensibility permit the writing of high-level programs such as CAD systems. However, extensibility also helps poor programmers to write incomprehensible code, which has given Forth a reputation as a "write-only language". Forth has been used successfully in large, complex projects, while applications developed by competent, disciplined professionals have proven to be easily maintained on evolving hardware platforms over decades of use.[3] Forth has a niche both in astronomical and space applications.[4] Forth is still used today in many embedded systems (small computerized devices) because of its portability, efficient memory use, short development time, and fast execution speed. It has been implemented efficiently on modern RISC processors, and processors that use Forth as machine language have been produced.[5] Other uses of Forth include the Open Firmware boot ROMs used by Apple, IBM, Sun, and OLPC XO-1; and the FICL-based first stage boot controller of the FreeBSD operating system.
History
Forth evolved from Charles H. Moore's personal programming system, which had been in continuous development since 1958.[6] Forth was first exposed to other programmers in the early 1970s, starting with Elizabeth Rather at the US National Radio Astronomy Observatory.[6] After their work at NRAO, Charles Moore and Elizabeth Rather formed FORTH, Inc. in 1973, refining and porting Forth systems to dozens of other platforms in the next decade.
Forth is so named because in 1968 "[t]he file holding the interpreter was labeled FOURTH, for 4th (next) generation software — but the IBM 1130 operating system restricted file names to 5 characters."[7] Moore saw Forth as a successor to compile-link-go third-generation programming languages, or software for "fourth generation" hardware, not a fourth-generation programming language as the term has come to be used.
Because Charles Moore had frequently moved from job to job over his career, an early pressure on the developing language was ease of porting to different computer architectures. A Forth system has often been used to bring up new hardware. For example, Forth was the first resident software on the new Intel 8086 chip in 1978 and MacFORTH was the first resident development system for the first Apple Macintosh in 1984.[6]
FORTH, Inc's microFORTH was developed for the Intel 8080, Motorola 6800, and Zilog Z80 microprocessors starting in 1976. MicroFORTH was later used by hobbyists to generate Forth systems for other architectures, such as the 6502 in 1978. Wide dissemination finally led to standardization of the language. Common practice was codified in the de facto standards FORTH-79[8] and FORTH-83[9] in the years 1979 and 1983, respectively. These standards were unified by ANSI in 1994, commonly referred to as ANS Forth.[10]
Forth became very popular in the 1980s[11] because it was well suited to the small microcomputers of that time, as it is compact and portable. At least one home computer, the British Jupiter ACE, had Forth in its ROM-resident operating system. The Canon Cat also used Forth for its system programming. Rockwell also produced single-chip microcomputers with resident Forth kernels, the R65F11 and R65F12. A complete family tree at TU-Wien.
Programmer's perspective
Forth relies heavily on explicit use of a data stack and reverse Polish notation (RPN or postfix notation), commonly used in calculators from Hewlett-Packard. In RPN, the operator is placed after its operands, as opposed to the more common infix notation where the operator is placed between its operands. Postfix notation makes the language easier to parse and extend; Forth does not use a BNF grammar, and does not have a monolithic compiler. Extending the compiler only requires writing a new word, instead of modifying a grammar and changing the underlying implementation.
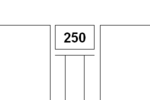
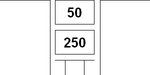
Using RPN, one could get the result of the mathematical expression (25 * 10 + 50) this way:
25 10 * 50 + . <cr> 300 ok
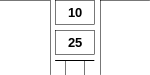
This command line first puts the numbers 25 and 10 on the implied stack.
The word * multiplies the two numbers on the top of the stack and replaces them with their product.
Then the number 50 is placed on the stack.
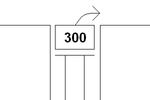
The word + adds it to the previous product. Finally, the . command prints the result to the user's terminal.[12]
Even Forth's structural features are stack-based. For example:
: FLOOR5 ( n -- n' ) DUP 6 < IF DROP 5 ELSE 1 - THEN ;
This code defines a new word (again, 'word' is the term used for a subroutine) called FLOOR5 using the following commands: DUP duplicates the number on the stack; 6 places a 6 on top of the stack; < compares the top two numbers on the stack (6 and the DUPed input), and replaces them with a true-or-false value; IF takes a true-or-false value and chooses to execute commands immediately after it or to skip to the ELSE; DROP discards the value on the stack; and THEN ends the conditional. The text in parentheses is a comment, advising that this word expects a number on the stack and will return a possibly changed number. The FLOOR5 word is equivalent to this function written in the C programming language using ternary operator:
int floor5(int v) { return (v < 6) ? 5 : (v - 1); }
This function is written more succinctly as:
: FLOOR5 ( n -- n' ) 1- 5 MAX ;
You would run this word as follows:
1 FLOOR5 . <cr> 5 ok 8 FLOOR5 . <cr> 7 ok
First the interpreter pushes a number (1 or 8) onto the stack, then it calls FLOOR5, which pops off this number again and pushes the result. Finally, a call to "." pops the result and prints it to the user's terminal.
Facilities
Forth parsing is simple, despite having no explicit grammar. The interpreter reads a line of input from the user input device, which is then parsed for a word using spaces as a delimiter; some systems recognise additional whitespace characters. When the interpreter finds a word, it tries to look the word up in the dictionary. If the word is found, the interpreter executes the code associated with the word, and then returns to parse the rest of the input stream. If the word isn't found, the word is assumed to be a number, and an attempt is made to convert it into a number and push it on the stack; if successful, the interpreter continues parsing the input stream. Otherwise, if both the lookup and number conversion fails, the interpreter prints the word followed by an error message indicating the word is not recognised, flushes the input stream, and waits for new user input.[13]
The definition of a new word is started with the word : (colon) and ends with the word ; (semi-colon). For example
: X DUP 1+ . . ;
will compile the word X, and makes the name findable in the dictionary. When executed by typing 10 X at the console this will print 11 10.[14]
Most Forth systems include a specialized assembler that produces executable words. The assembler is a special dialect of the compiler. Forth assemblers often use a reverse-polish syntax in which the parameters of an instruction precede the instruction. The usual design of a Forth assembler is to construct the instruction on the stack, then copy it into memory as the last step. Registers may be referenced by the name used by the manufacturer, numbered (0..n, as used in the actual operation code) or named for their purpose in the Forth system: e.g. "S" for the register used as a stack pointer.[15]
Operating system, files, and multitasking
Classic Forth systems traditionally use neither operating system nor file system. Instead of storing code in files, source-code is stored in disk blocks written to physical disk addresses. The word BLOCK is employed to translate the number of a 1K-sized block of disk space into the address of a buffer containing the data, which is managed automatically by the Forth system. Some implement contiguous disk files using the system's disk access, where the files are located at fixed disk block ranges. Usually these are implemented as fixed-length binary records, with an integer number of records per disk block. Quick searching is achieved by hashed access on key data.
Multitasking, most commonly cooperative round-robin scheduling, is normally available (although multitasking words and support are not covered by the ANSI Forth Standard). The word PAUSE is used to save the current task's execution context, to locate the next task, and restore its execution context. Each task has its own stacks, private copies of some control variables and a scratch area. Swapping tasks is simple and efficient; as a result, Forth multitaskers are available even on very simple microcontrollers such as the Intel 8051, Atmel AVR, and TI MSP430.[16]
By contrast, some Forth systems run under a host operating system such as Microsoft Windows, Linux or a version of Unix and use the host operating system's file system for source and data files; the ANSI Forth Standard describes the words used for I/O. Other non-standard facilities include a mechanism for issuing calls to the host OS or windowing systems, and many provide extensions that employ the scheduling provided by the operating system. Typically they have a larger and different set of words from the stand-alone Forth's PAUSE word for task creation, suspension, destruction and modification of priority.
Self-compilation and cross compilation
A fully featured Forth system with all source code will compile itself, a technique commonly called meta-compilation by Forth programmers (although the term doesn't exactly match meta-compilation as it is normally defined). The usual method is to redefine the handful of words that place compiled bits into memory. The compiler's words use specially-named versions of fetch and store that can be redirected to a buffer area in memory. The buffer area simulates or accesses a memory area beginning at a different address than the code buffer. Such compilers define words to access both the target computer's memory, and the host (compiling) computer's memory.[17]
After the fetch and store operations are redefined for the code space, the compiler, assembler, etc. are recompiled using the new definitions of fetch and store. This effectively reuses all the code of the compiler and interpreter. Then, the Forth system's code is compiled, but this version is stored in the buffer. The buffer in memory is written to disk, and ways are provided to load it temporarily into memory for testing. When the new version appears to work, it is written over the previous version.
There are numerous variations of such compilers for different environments. For embedded systems, the code may instead be written to another computer, a technique known as cross compilation, over a serial port or even a single TTL bit, while keeping the word names and other non-executing parts of the dictionary in the original compiling computer. The minimum definitions for such a forth compiler are the words that fetch and store a byte, and the word that commands a Forth word to be executed. Often the most time-consuming part of writing a remote port is constructing the initial program to implement fetch, store and execute, but many modern microprocessors have integrated debugging features (such as the Motorola CPU32) that eliminate this task.[18]
Structure of the language
The basic data structure of Forth is the "dictionary" which maps "words" to executable code or named data structures. The dictionary is laid out in memory as a tree of linked lists with the links proceeding from the latest (most recently) defined word to the oldest, until a sentinel, usually a NULL pointer, is found. A context switch causes a list search to start at a different leaf. A linked list search continues as the branch merges into the main trunk leading eventually back to the sentinel, the root. There can be several dictionaries. In rare cases such as meta-compilation a dictionary might be isolated and stand-alone. The effect resembles that of nesting namespaces and can overload keywords depending on the context.
A defined word generally consists of head and body with the head consisting of the name field (NF) and the link field (LF) and body consisting of the code field (CF) and the parameter field (PF).
Head and body of a dictionary entry are treated separately because they may not be contiguous. For example, when a Forth program is recompiled for a new platform, the head may remain on the compiling computer, while the body goes to the new platform. In some environments (such as embedded systems) the heads occupy memory unnecessarily. However, some cross-compilers may put heads in the target if the target itself is expected to support an interactive Forth.[19]
Dictionary entry
The exact format of a dictionary entry is not prescribed, and implementations vary. However, certain components are almost always present, though the exact size and order may vary. Described as a structure, a dictionary entry might look this way:[20]
structure byte: flag \ 3bit flags + length of word's name char-array: name \ name's runtime length isn't known at compile time address: previous \ link field, backward ptr to previous word address: codeword \ ptr to the code to execute this word any-array: parameterfield \ unknown length of data, words, or opcodes end-structure forthword
The name field starts with a prefix giving the length of the word's name (typically up to 32 bytes), and several bits for flags. The character representation of the word's name then follows the prefix. Depending on the particular implementation of Forth, there may be one or more NUL ('\0') bytes for alignment.
The link field contains a pointer to the previously defined word. The pointer may be a relative displacement or an absolute address that points to the next oldest sibling.
The code field pointer will be either the address of the word which will execute the code or data in the parameter field or the beginning of machine code that the processor will execute directly. For colon defined words, the code field pointer points to the word that will save the current Forth instruction pointer (IP) on the return stack, and load the IP with the new address from which to continue execution of words. This is the same as what a processor's call/return instructions does.
Structure of the compiler
The compiler itself is not a monolithic program. It consists of Forth words visible to the system, and usable by a programmer. This allows a programmer to change the compiler's words for special purposes.
The "compile time" flag in the name field is set for words with "compile time" behavior. Most simple words execute the same code whether they are typed on a command line, or embedded in code. When compiling these, the compiler simply places code or a threaded pointer to the word.[14]
The classic examples of compile-time words are the control structures such as IF and WHILE. All of Forth's control structures, and almost all of its compiler are implemented as compile-time words. All of Forth's control flow words are executed during compilation to compile various combinations of the primitive words BRANCH and ?BRANCH (branch if false). During compilation, the data stack is used to support control structure balancing, nesting, and backpatching of branch addresses. The snippet:
... DUP 6 < IF DROP 5 ELSE 1 - THEN ...
would be compiled to the following sequence inside of a definition:
... DUP LIT 6 < ?BRANCH 5 DROP LIT 5 BRANCH 3 LIT 1 - ...
The numbers after BRANCH represent relative jump addresses. LIT is the primitive word for pushing a "literal" number onto the data stack.
Compilation state and interpretation state
The word : (colon) parses a name as a parameter, creates a dictionary entry (a colon definition) and enters compilation state. The interpreter continues to read space-delimited words from the user input device. If a word is found, the interpreter executes the compilation semantics associated with the word, instead of the interpretation semantics. The default compilation semantics of a word are to append its interpretation semantics to the current definition.[14]
The word ; (semi-colon) finishes the current definition and returns to interpretation state. It is an example of a word whose compilation semantics differ from the default. The interpretation semantics of ; (semi-colon), most control flow words, and several other words are undefined in ANS Forth, meaning that they must only be used inside of definitions and not on the interactive command line.[14]
The interpreter state can be changed manually with the words [ (left-bracket) and ] (right-bracket) which enter interpretation state or compilation state, respectively. These words can be used with the word LITERAL to calculate a value during a compilation and to insert the calculated value into the current colon definition. LITERAL has the compilation semantics to take an object from the data stack and to append semantics to the current colon definition to place that object on the data stack.
In ANS Forth, the current state of the interpreter can be read from the flag STATE which contains the value true when in compilation state and false otherwise. This allows the implementation of so-called state-smart words with behavior that changes according to the current state of the interpreter.
Immediate words
The word IMMEDIATE marks the most recent colon definition as an immediate word, effectively replacing its compilation semantics with its interpretation semantics.[21] Immediate words are normally executed during compilation, not compiled but this can be overridden by the programmer, in either state. ; is an example of an immediate word. In ANS Forth, the word POSTPONE takes a name as a parameter and appends the compilation semantics of the named word to the current definition even if the word was marked immediate. Forth-83 defined separate words COMPILE and [COMPILE] to force the compilation of non-immediate and immediate words, respectively.
Unnamed words and execution tokens
In ANS Forth, unnamed words can be defined with the word :NONAME which compiles the following words up to the next ; (semi-colon) and leaves an execution token on the data stack. The execution token provides an opaque handle for the compiled semantics, similar to the function pointers of the C programming language.
Execution tokens can be stored in variables. The word EXECUTE takes an execution token from the data stack and performs the associated semantics. The word COMPILE, (compile-comma) takes an execution token from the data stack and appends the associated semantics to the current definition.
The word ' (tick) takes the name of a word as a parameter and returns the execution token associated with that word on the data stack. In interpretation state, ' RANDOM-WORD EXECUTE is equivalent to RANDOM-WORD.[22]
Parsing words and comments
The words : (colon), POSTPONE, ' (tick) and :NONAME are examples of parsing words that take their arguments from the user input device instead of the data stack. Another example is the word ( (paren) which reads and ignores the following words up to and including the next right parenthesis and is used to place comments in a colon definition. Similarly, the word \ (backslash) is used for comments that continue to the end of the current line. To be parsed correctly, ( (paren) and \ (backslash) must be separated by whitespace from the following comment text.
Structure of code
In most Forth systems, the body of a code definition consists of either machine language, or some form of threaded code. The original Forth which follows the informal FIG standard (Forth Interest Group), is a TIL (Threaded Interpretive Language). This is also called indirect-threaded code, but direct-threaded and subroutine threaded Forths have also become popular in modern times. The fastest modern Forths use subroutine threading, insert simple words as macros, and perform peephole optimization or other optimizing strategies to make the code smaller and faster.[23]
Data objects
When a word is a variable or other data object, the CF points to the runtime code associated with the defining word that created it. A defining word has a characteristic "defining behavior" (creating a dictionary entry plus possibly allocating and initializing data space) and also specifies the behavior of an instance of the class of words constructed by this defining word. Examples include:
VARIABLE- Names an uninitialized, one-cell memory location. Instance behavior of a
VARIABLEreturns its address on the stack. CONSTANT- Names a value (specified as an argument to
CONSTANT). Instance behavior returns the value. CREATE- Names a location; space may be allocated at this location, or it can be set to contain a string or other initialized value. Instance behavior returns the address of the beginning of this space.
Forth also provides a facility by which a programmer can define new application-specific defining words, specifying both a custom defining behavior and instance behavior. Some examples include circular buffers, named bits on an I/O port, and automatically-indexed arrays.
Data objects defined by these and similar words are global in scope. The function provided by local variables in other languages is provided by the data stack in Forth (although Forth also has real local variables). Forth programming style uses very few named data objects compared with other languages; typically such data objects are used to contain data which is used by a number of words or tasks (in a multitasked implementation).[24]
Forth does not enforce consistency of data type usage; it is the programmer's responsibility to use appropriate operators to fetch and store values or perform other operations on data.
Programming
Words written in Forth are compiled into an executable form. The classical "indirect threaded" implementations compile lists of addresses of words to be executed in turn; many modern systems generate actual machine code (including calls to some external words and code for others expanded in place). Some systems have optimizing compilers. Generally speaking, a Forth program is saved as the memory image of the compiled program with a single command (e.g., RUN) that is executed when the compiled version is loaded.
During development, the programmer uses the interpreter to execute and test each little piece as it is developed. Most Forth programmers therefore advocate a loose top-down design, and bottom-up development with continuous testing and integration.[25]
The top-down design is usually separation of the program into "vocabularies" that are then used as high-level sets of tools to write the final program. A well-designed Forth program reads like natural language, and implements not just a single solution, but also sets of tools to attack related problems.[26]
Code examples
Hello world
For an explanation of the tradition of programming "Hello World", see Hello world program.
One possible implementation:
: HELLO ( -- ) CR ." Hello, world!" ; HELLO <cr> Hello, world!
The word CR (Carriage Return) causes the following output to be displayed on a new line. The parsing word ." (dot-quote) reads a double-quote delimited string and appends code to the current definition so that the parsed string will be displayed on execution. The space character separating the word ." from the string Hello, world! is not included as part of the string. It is needed so that the parser recognizes ." as a Forth word.
A standard Forth system is also an interpreter, and the same output can be obtained by typing the following code fragment into the Forth console:
CR .( Hello, world!)
.( (dot-paren) is an immediate word that parses a parenthesis-delimited string and displays it. As with the word ." the space character separating .( from Hello, world! is not part of the string.
The word CR comes before the text to print. By convention, the Forth interpreter does not start output on a new line. Also by convention, the interpreter waits for input at the end of the previous line, after an ok prompt. There is no implied 'flush-buffer' action in Forth's CR, as sometimes is in other programming languages.
Mixing compilation state and interpretation state
Here is the definition of a word EMIT-Q which when executed emits the single character Q:
: EMIT-Q 81 ( the ASCII value for the character 'Q' ) EMIT ;
This definition was written to use the ASCII value of the Q character (81) directly. The text between the parentheses is a comment and is ignored by the compiler. The word EMIT takes a value from the data stack and displays the corresponding character.
The following redefinition of EMIT-Q uses the words [ (left-bracket), ] (right-bracket), CHAR and LITERAL to temporarily switch to interpreter state, calculate the ASCII value of the Q character, return to compilation state and append the calculated value to the current colon definition:
: EMIT-Q [ CHAR Q ] LITERAL EMIT ;
The parsing word CHAR takes a space-delimited word as parameter and places the value of its first character on the data stack. The word [CHAR] is an immediate version of CHAR. Using [CHAR], the example definition for EMIT-Q could be rewritten like this:
: EMIT-Q [CHAR] Q EMIT ; \ Emit the single character 'Q'
This definition used \ (backslash) for the describing comment.
Both CHAR and [CHAR] are predefined in ANS Forth. Using IMMEDIATE and POSTPONE, [CHAR] could have been defined like this:
: [CHAR] CHAR POSTPONE LITERAL ; IMMEDIATE
A complete RC4 cipher program
In 1987 Ron Rivest developed the RC4 cipher-system for RSA Data Security, Inc. The code is extremely simple and can be written by most programmers from the description.
We have an array of 256 bytes, all different. Every time the array is used it changes by swapping two bytes. The swaps are controlled by counters i and j, each initially 0. To get a new i, add 1. To get a new j, add the array byte at the new i. Exchange the array bytes at i and j. The code is the array byte at the sum of the array bytes at i and j. This is XORed with a byte of the plaintext to encrypt, or the ciphertext to decrypt. The array is initialized by first setting it to 0 through 255. Then step through it using i and j, getting the new j by adding to it the array byte at i and a key byte, and swapping the array bytes at i and j. Finally, i and j are set to 0. All additions are modulo 256.
The following Standard Forth version uses Core words only.
0 VALUE ii 0 VALUE jj CREATE S[] 256 CHARS ALLOT
: ARCFOUR ( c -- x ) ii 1+ DUP TO ii 255 AND ( -- i ) S[] + DUP C@ ( -- 'S[i] S[i] ) DUP jj + 255 AND DUP TO jj ( -- 'S[i] S[i] j ) S[] + DUP C@ >R ( -- 'S[i] S[i] 'S[j] ) OVER SWAP C! ( -- 'S[i] S[i] ) R@ ROT C! ( -- S[i] ) R> + ( -- S[i]+S[j] ) 255 AND S[] + C@ ( -- c x ) XOR ;
: ARCFOUR-INIT ( key len -- ) 256 MIN LOCALS| len key | 256 0 DO I S[] I + C! LOOP 0 TO jj 256 0 DO ( key len -- ) key I len MOD + C@ S[] I + C@ + jj + 255 AND TO jj S[] I + DUP C@ SWAP ( c1 addr1 ) S[] jj + DUP C@ ( c1 addr1 addr2 c2 ) ROT C! C! LOOP 0 TO ii 0 TO jj ;
This is one of many tests to validate the code.
CREATE KEY: 64 CHARS ALLOT
: !KEY ( c1 c2 ... cn n—store the specified key of length n ) DUP 63 U> ABORT" key too long (<64)" DUP KEY: C! KEY: + KEY: 1+ SWAP ?DO I C! -1 +LOOP ; HEX 61 8A 63 D2 FB 5 !KEY
KEY: COUNT ARCFOUR-INIT
CR DC ARCFOUR 2 .R SPACE EE ARCFOUR 2 .R SPACE 4C ARCFOUR 2 .R SPACE F9 ARCFOUR 2 .R SPACE 2C ARCFOUR 2 .R
CR .( Should be: F1 38 29 C9 DE )
Implementations
Because the Forth virtual machine is simple to implement and has no standard reference implementation, there are a plethora of implementations of the language. In addition to supporting the standard varieties of desktop computer systems (POSIX, Microsoft Windows, Mac OS X), many of these Forth systems also target a variety of embedded systems. Listed here are the some of the more prominent systems which conform to the 1994 ANS Forth standard.
- Gforth - a portable ANS Forth implementation from the GNU Project
- Forth Inc. - founded by the originators of Forth, sells desktop (SwiftForth) and embedded (SwiftX) ANS Forth
- MPE Ltd. - sells highly-optimized desktop (VFX) and embedded ANS Forth compilers
- Open Firmware - a bootloader and BIOS standard based on ANS Forth
- Freely available implementations
- Commercial implementations
- A more up-to-date index of Forth systems, organized by platform
See also
- colorForth
- pforth
- Factor
- Joy
- STOIC
- Open Firmware
- Stack machine
- Charles H. Moore
References
- ↑ NASA applications of Forth
- ↑ Forth 200x standards effort
- ↑ "Forth Success Stories". http://www.forth.org/successes.html. Retrieved 2006-06-09.
- ↑ "Space Related Applications of Forth". http://forth.gsfc.nasa.gov/. Retrieved 2007-09-04.
- ↑ "Forth Chips Page". pp. 54. http://www.ultratechnology.com/. Retrieved 2006-06-09.
- ↑ 6.0 6.1 6.2 "The Evolution of Forth". ACM SIGPLAN Notices, Volume 28, No. 3. March, 1993. ACM SIGPLAN History of Programming Languages Conference. April 1993. http://www.forth.com/resources/evolution/index.html.
- ↑ Moore, Charles H (1991). "Forth - The Early Years". http://www.colorforth.com/HOPL.html. Retrieved 2006-06-03.
- ↑ "The Forth-79 Standard" (PDF). https://mywebspace.wisc.edu/lnmaurer/web/forth/Forth-79.pdf.
- ↑ "The Forth-83 Standard". http://forth.sourceforge.net/standard/fst83/.
- ↑ "Programming Languages: Forth". ANSI technical committee X3J14. 24 March 1994. http://www.taygeta.com/forth/dpans.html. Retrieved 2006-06-03.
- ↑ "The Forth Language", BYTE Magazine 5 (8), 1980
- ↑ Brodie, Leo (1987) (paperback). Starting Forth (Second ed.). Prentice-Hall. pp. 20. ISBN 0-13-843079-9.
- ↑ Brodie, Leo (1987) (paperback). Starting Forth (Second ed.). Prentice-Hall. pp. 14. ISBN 0-13-843079-9.
- ↑ 14.0 14.1 14.2 14.3 Brodie, Leo (1987) (paperback). Starting Forth (Second ed.). Prentice-Hall. pp. 16. ISBN 0-13-843079-9.
- ↑ Rodriguez, Brad. "B.Y.O.ASSEMBLER". http://www.zetetics.com/bj/papers/6809asm.txt. Retrieved 2006-06-19.
- ↑ Rodriguez, Brad. "MULTITASKING 8051 CAMELFORTH" (PDF). http://www.zetetics.com/bj/papers/8051task.pdf. Retrieved 2006-06-19.
- ↑ Rodriguez, Brad (July 1995). "MOVING FORTH". http://www.zetetics.com/bj/papers/moving8.htm. Retrieved 2006-06-19.
- ↑ Shoebridge, Peter (1998-12-21). "Motorola Background Debugging Mode Driver for Windows NT". http://www.zeecube.com/archive/bdm/index.htm. Retrieved 2006-06-19.
- ↑ Martin, Harold M. (March 1991). "Developing a tethered Forth model". ACM Press. http://portal.acm.org/citation.cfm?id=122089.122091&coll=portal&dl=ACM&idx=J696&part=periodical&WantType=periodical&title=ACM%20SIGFORTH%20Newsletter. Retrieved 2006-06-19.
- ↑ Brodie, Leo (1987) (paperback). Starting Forth (Second ed.). Prentice-Hall. pp. 200–202. ISBN 0-13-843079-9.
- ↑ Brodie, Leo (1987) (paperback). Starting Forth (Second ed.). Prentice-Hall. pp. 273. ISBN 0-13-843079-9.
- ↑ Brodie, Leo (1987) (paperback). Starting Forth (Second ed.). Prentice-Hall. pp. 199. ISBN 0-13-843079-9.
- ↑ Ertl, M. Anton; Gregg, David. "Implementation Issues for Superinstructions in Gforth" (PDF). http://dec.bournemouth.ac.uk/forth/euro/ef03/ertl-gregg03.pdf. Retrieved 2006-06-19.
- ↑ Brodie, Leo (1987). "Under The Hood" (paperback). Starting Forth (2nd ed.). Prentice-Hall. pp. 241. ISBN 0-13-843079-9. "To summarize, there are three kinds of variables: System variables contain values used by the entire Forth system. User variables contain values that are unique for each task, even though the definitions can be used by all tasks in the system. Regular variables can be accessible either system-wide or within a single task only, depending upon whether they are defined within
OPERATORor within a private task." - ↑ Brodie, Leo (1984) (paperback). Thinking Forth. Prentice-Hall. ISBN 0-13-917568-7.
- ↑ The classic washing machine example describes the process of creating a vocabulary to naturally represent the problem domain in a readable way.
Further reading
- Biancuzzi, Federico; Shane Warden (2009). "Chapter Four [A conversation with Chuck Moore]" (paperback). Masterminds of Programming, Conversations with the Creators of Major Programming Languages. O'REILLY. ISBN 978-0-596-51517-1.
- Brodie, Leo (2007). Marcel Hendrix. ed (Online book). Starting Forth. Marlin Ouverson (Web edition ed.). FORTH, Inc.. http://www.forth.com/starting-forth/index.html. Retrieved 2007-09-29.
- Brodie, Leo (2004). Bernd Paysan. ed (PDF Online book). Thinking Forth. ISBN 0-9764587-0-5. http://thinking-forth.sourceforge.net. Retrieved 2008-09-15.
- Conklin, Edward K.; Elizabeth D. Rather et al. (8 September 2007) (paperback). Forth Programmer's Handbook (3rd ed.). BookSurge Publishing. pp. 274. ISBN 1-4196-7549-4. http://www.forth.com/forth/forth-books.html.
- Rather, Elizabeth D. (spiral bound). Forth Application Techniques. Forth Inc.. pp. 158. ISBN 0-9662156-1-3. http://www.forth.com/forth/forth-books.html.
- Pelc, Stephen F. (spiral bound). Programming Forth. MicroProcessor Engineering Ltd. pp. 188. http://www.mpeforth.com/books.htm.
- Kelly, Mahlon G.; Nicholas Spies. FORTH: A Text and Reference. Prentice-Hall. ISBN 0-13-326331-2.
- Koopman, Jr, Philip J. (1989) (hardcover). Stack Computers: The New Wave. Ellis Horwood Limited. ISBN 0-7458-0418-7. http://www.ece.cmu.edu/~koopman/stack_computers/index.html.
- Pountain, Dick (1987) (paperback). Object-oriented Forth: Implementation of Data Structures. Harcourt Brace Jovanovich. ISBN 0-12-563570-2.
- Payne, William (19 December 1990). Embedded Controller Forth for the 8051 Family. Elsevier. pp. 528. ISBN 978-0125475709.
External links
- comp.lang.forth - Usenet newsgroup with active Forth discussion
- Forth Chips Page — Forth in hardware
- A Beginner's Guide to Forth by J.V. Noble
- Forth Links
- Various Forth variants and ANSI docs
- Starting FORTH online version of the book Starting FORTH by Leo Brodie published in 1981.
- Thinking Forth Project includes the seminal (and previously out of print) book Thinking Forth by Leo Brodie published in 1984, now available both as a PDF and in hardcopy as a reprint, with some revisions to ensure current compatibility.
- Primary Forth author Leo Brodie's homepage.
- Computerworld Interview with Charles H. Moore on Forth
- FORTH Retro Podcast in two parts (part I, part II)
- Forth at the Open Directory Project